Data Platform & streaming architecture
Context
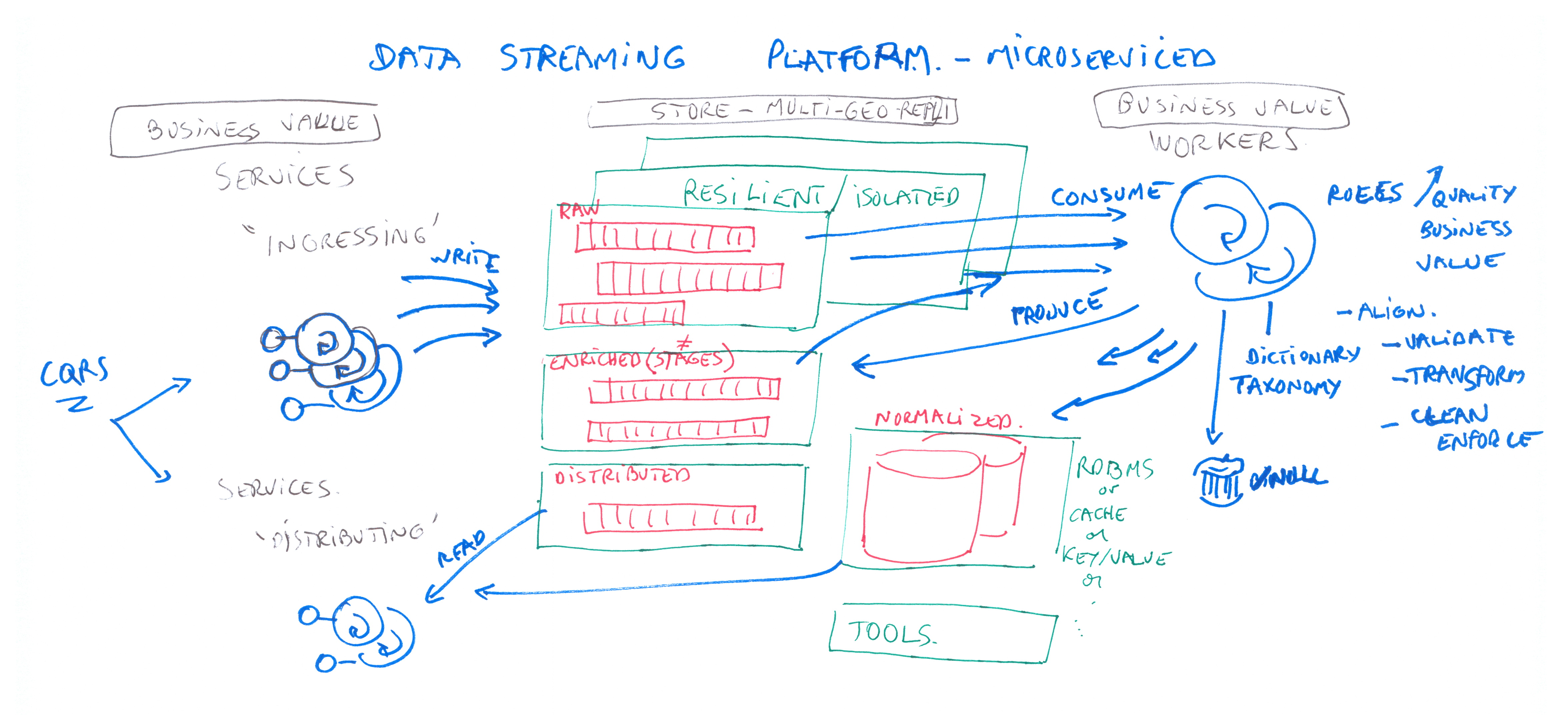
During many years now, driven by Big data/data-avid projects, streaming platform architecture (lambda or kappa ) is the pattern proposed for ingesting business-valued data into a persistant repository (database, key/value store/object /column storage).
ESB / Enterprise Service Bus, EAI Enterprise Application Integration was/are part of SOA projects also but with some notable differences:
- implementation of Enterprise Integration Pattern like internal routing , based on content
- point to point communications / based on “old” Message Oriented Middleware with lack of performance for PubSub channels, and possible complexity(integration spaghetti)
- “Hub and spoke” message broker / decouple producer & consumer for reusable data but with a pivot format
- GUI for designing BPM
- lot of compute/network overhead with data manipulations
Such products are leading to more and more complexity , due to the break of Single Responsability Principle (SOLID) / central processing
Event-driven / Streaming use cases are not adequately implemented by ESB products (latency for write, scaling).
Solutions for the resiliency of streaming events
=> Distributed message systems with low latency write and immutable
Such as Log Data Store :
- Apache Kafka
- Apache Pulsar
- Apache Bookkeeper
- Azure Cosmos DB Change Feed
- Azure EventHub
- DistributedLog
- Chronicle Queue
- Pravega …
Industry
Apache Kafka is supported (commercial license) mainly by Confluent and Cloudera (Hortonworks)
October 2019: Splunk agrees to acquire Streamlio, a company aimed to support Apache Pulsar
Solutions (opensource)
Apache Kafka
Implements real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, wicked fast, and runs in production in thousands of companies.
Kafka is a great publish/subscribe system (only/no PtP) distributed (with several brokers and local storage) or monolithic (with co-located storage) Data are stored inside one to several Partitions as a Topic, (local internal storage of brokers). Data is indexed by offset id in the topic.
There are plenty of client library implemented the same API. (strong pros argue)
https://en.wikipedia.org/wiki/Apache_Kafka
Kafka requires a process supervisor (Apache Zookeeper)
Confluent proposes a SQL layer (KSQL propriertary library). their strategy is to sell Kafka as a DBMS (would lead to perf problems?)
https://medium.com/@durgaswaroop/a-practical-introduction-to-kafka-storage-internals-d5b544f6925f
ETCD
https://etcd.io/ Distributed , reliable Key/value store
embedded inside Kubernetes for service discoverty and cluster state/config
Apache BookKeeper
https://bookkeeper.apache.org/
Lowlatency storage service (scalable / distributed)
Redis
https://redis.io/
messagebroker / in memory (low latency) data structure, or key/value database
Apache Pulsar
• Building a unified data processing stack with Apache Pulsar and Apache Spark :
Apache Pulsar is a cloud-native event streaming system. It deploys a cloud-native architecture and a segment-centric storage. Pulsar provides a unified data view on both historic and real-time data. Hence it can be easily integrated with a unified computing engine to build a unified data processing stack.
Pros
- No limit on Topics numbers
- PubSub AND Message Queuing
- based on Bookkeeper(for persistence)
Cons
- less REX than Kafka
Bookmark links
Kafka is not a database, Kafka streams lacks of snapshots/checkpointing
Why Nutanix Beam went ahead with Apache Pulsar instead of Apache Kafka?
We helped Airbus create a real-time big data project streaming 2+ billion events per day